2025年4月7日,每年都備受矚目的斯坦福AI指數(shù)報告,重磅發(fā)布了!
這份報告由斯坦福大學以人為本AI研究員發(fā)布,代表著每年AI領(lǐng)域最核心和前沿的動向總結(jié)。
今年,這份報告長達456頁,拋出不少驚人觀點。

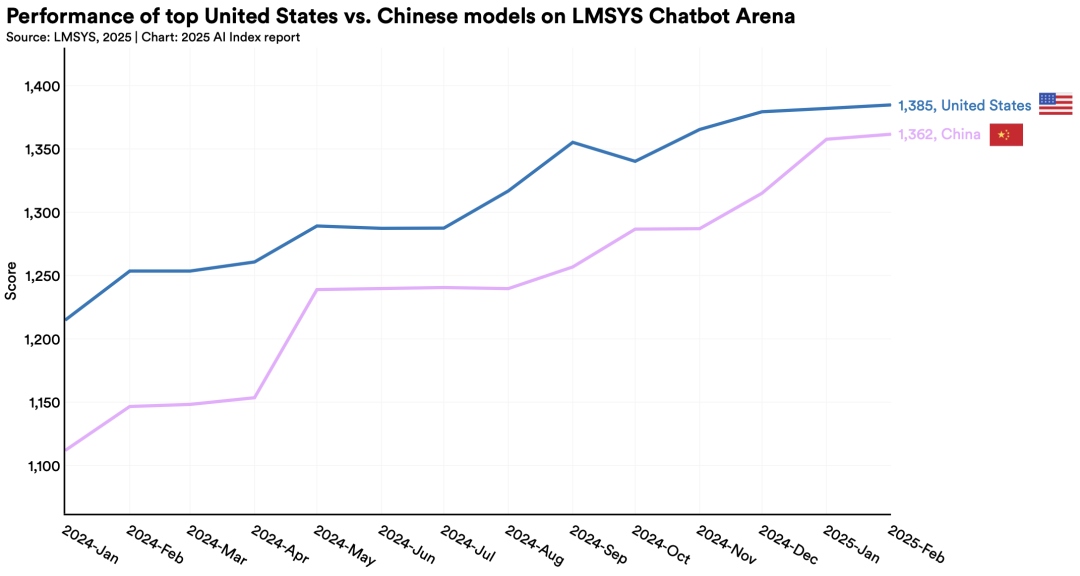
比如,如今在2025年,中美頂級AI模型的性能差距已經(jīng)縮小到了0.3%(2023年,這一數(shù)字還是20%),中國模型正在快速追趕美國的領(lǐng)先地位!
而DeepSeek領(lǐng)銜的開放權(quán)重模型,更是以1.7%之差,逼宮各大閉源巨頭。前者和后者的差距,已經(jīng)由2024年的8%,縮小至2025年的1.7%。
當然,目前從行業(yè)主導企業(yè)來看,美國仍然領(lǐng)先于中國。在2024年,90%的知名AI模型來自企業(yè),美國以40個模型領(lǐng)先,中國有15個。
更
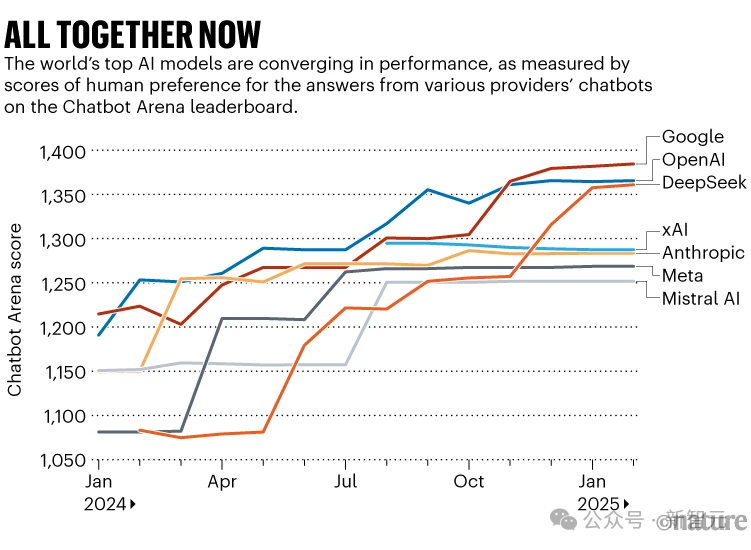
明顯的一個趨勢,就是如今大模型的性能已經(jīng)趨同!在2024年,TOP1和TOP10的模型的差距能有12%,但如今,它們的差距已經(jīng)越來越小,銳減至5%。

十二大亮點
最新的斯坦福HAI兩篇博文中,濃縮了2025年AI指數(shù)報告的十二大亮點。
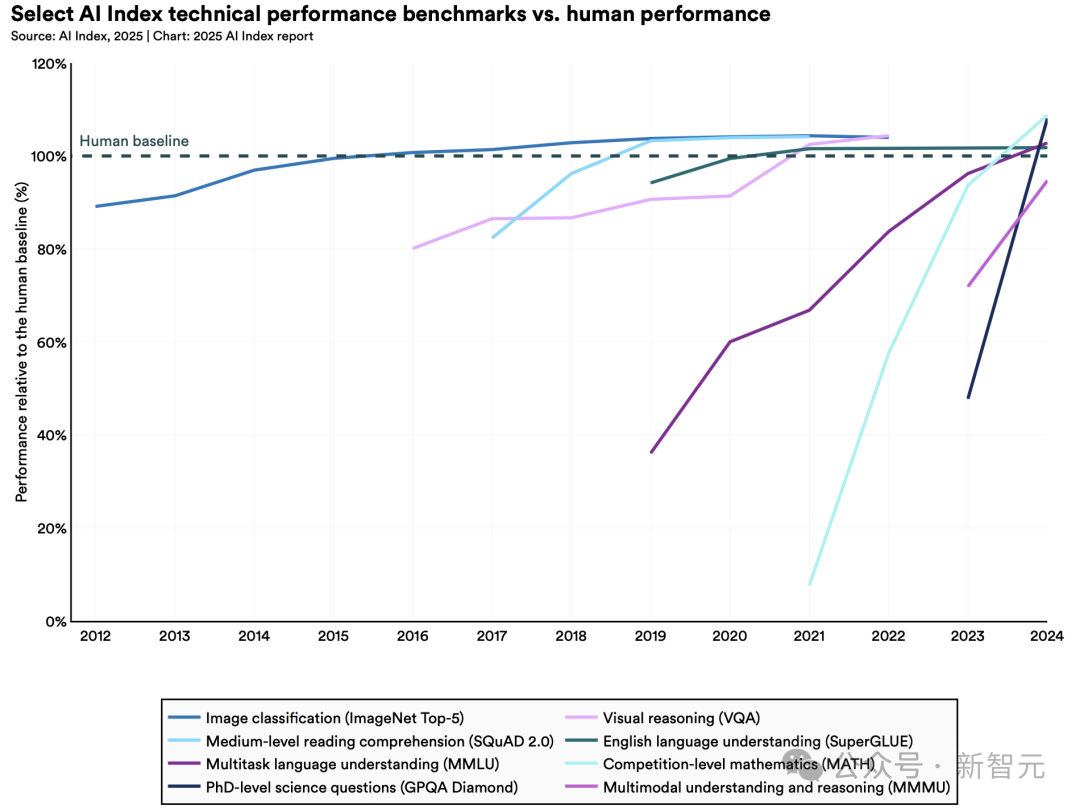
1. AI性能再攀高峰,從基準測試到視頻生成全面突破
2023年,研究人員推出了MMMU、GPQA和SWE-bench等新基準來測試先進AI系統(tǒng)的極限。
僅一年后,性能便大幅提升:AI在三項基準得分分別飆升18.8%、48.9%和67.3%。
不僅如此,AI在生成高質(zhì)量視頻方面取得重大突破,甚至,在某些場景下AI智能體甚至超越人類表現(xiàn)。
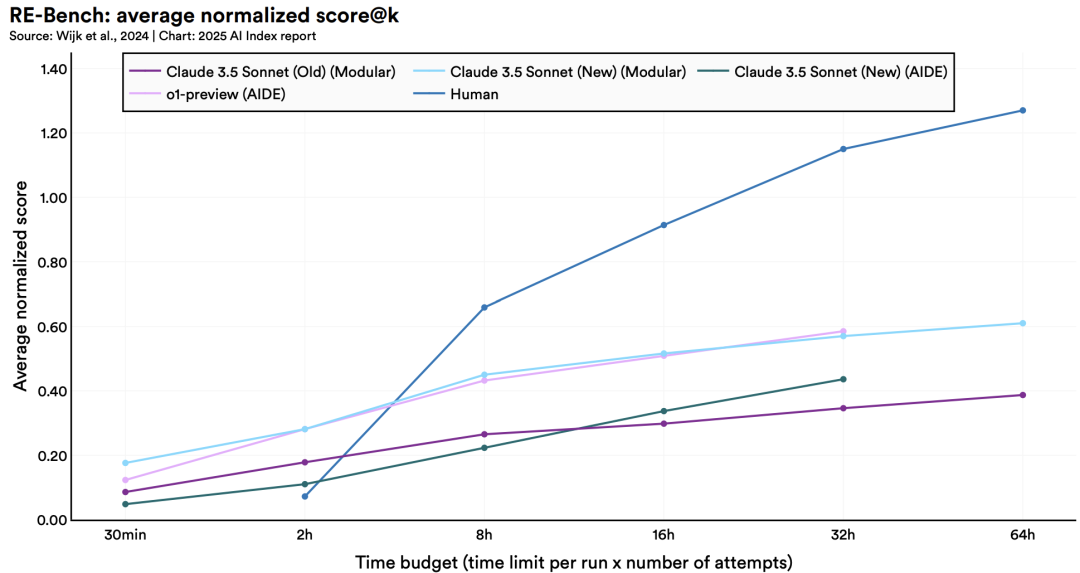
· 更有用智能體崛起
2024年發(fā)布的RE-Bench基準測試,為評估AI智能體復雜任務(wù)能力設(shè)立了嚴苛標準。
數(shù)據(jù)顯示:在短期任務(wù)(2小時內(nèi))場景下,頂級AI系統(tǒng)的表現(xiàn)可達人類專家的4倍;但當任務(wù)時限延長至32小時,人類則以2:1的優(yōu)勢反超。
值得注意的是,AI已在特定領(lǐng)域,如編寫特定類型代碼,展現(xiàn)出與人類相當?shù)膶I(yè)水平,且執(zhí)行效率更勝一籌。
2. 美國領(lǐng)跑頂尖模型研發(fā),但中國與之差距逐漸縮小
2024年,美國產(chǎn)出40個重要AI模型,遠超中國的15個和歐洲的3個。
然而,中國模型在性能上的差距正加速縮小:MMLU等基準測試中,中美AI差異從兩位數(shù)縮小至近乎持平。
同時,中國在AI學術(shù)論文和專利申請量上持續(xù)領(lǐng)跑,中東、拉美和東南亞地區(qū)也涌現(xiàn)出具有競爭力的模型。
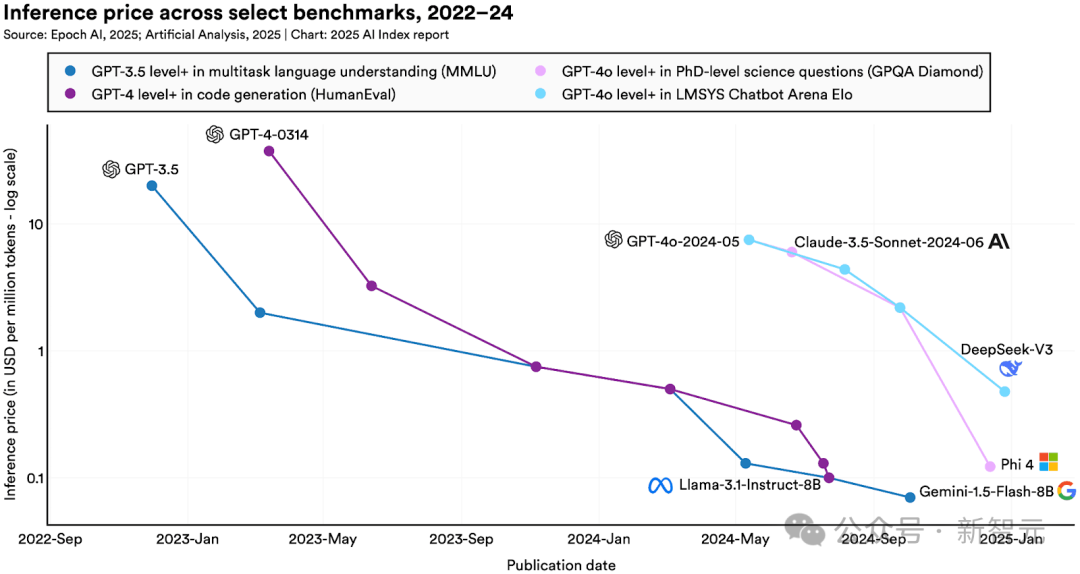
3. AI正變得高效且普惠,推理成本暴降280倍
隨著小模型性能提升,達到GPT-3.5水平的推理成本在兩年間下降280倍,硬件成本以每年30%的速度遞減,能效年提升率達40%。
更令人振奮的是,開源模型性能突飛猛進,部分基準測試中與閉源模型的差距從8%縮至1.7%。
· 大模型使用成本持續(xù)走低,年降幅最高900倍
在MMLU基準測試中達到GPT-3.5水平(MMLU準確率64.8%)的AI模型調(diào)用成本,已從2022年11月的20美元/每百萬token,驟降至2024年10月的0.07美元/每百萬token(谷歌DeepMind的Gemini-1.5-Flash-8B模型),18個月內(nèi)AI成本下降280倍。
視具體任務(wù)需求,LLM推理服務(wù)價格的年降幅可達9-900倍不等。
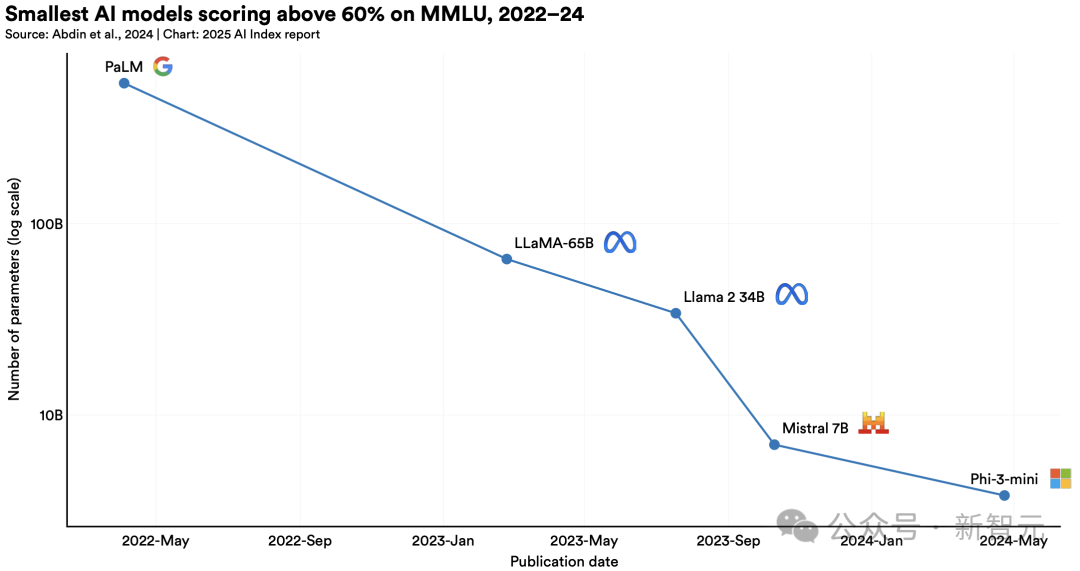
· 小模型性能顯著提升,參數(shù)暴減142倍
2022年,在大規(guī)模多任務(wù)語言理解(MMLU)基準測試中,得分超60%的最小模型是 PaLM,參數(shù)量為5400億。
到了2024年,微軟Phi-3-mini僅用38億參數(shù),就取得了同樣的實力。
這代表,兩年多的時間里模型參數(shù)減少了142倍。
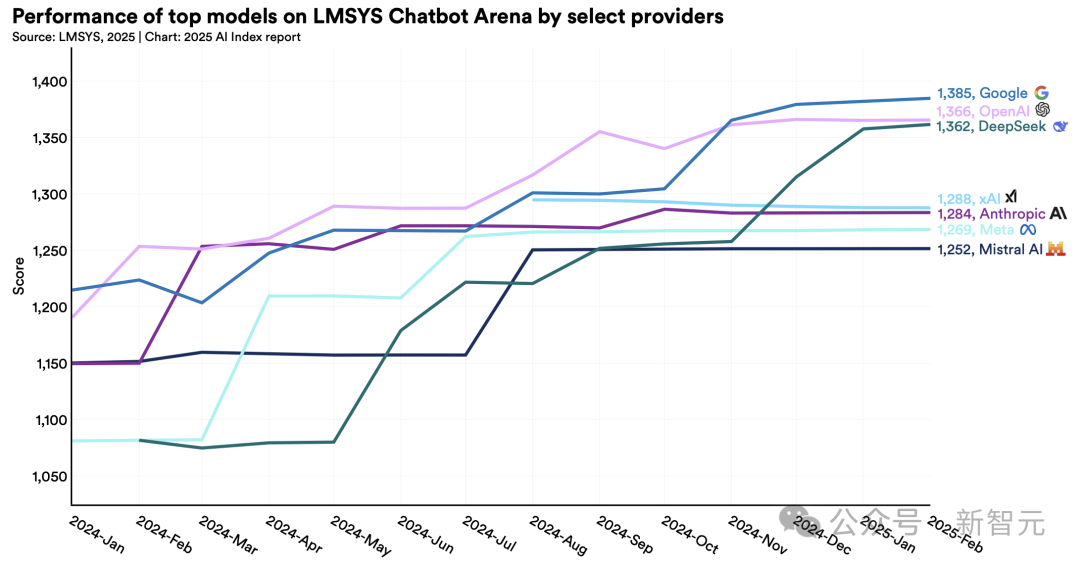
4. 科技巨頭稱霸AI前沿,但競爭白熱化
2024年,近90%的重要模型源自企業(yè),學術(shù)界則保持基礎(chǔ)研究優(yōu)勢。
模型規(guī)模呈指數(shù)增長:訓練算力每5個月翻番,數(shù)據(jù)集每8個月擴容一倍。
值得注意的是,頭部模型性能差距顯著縮小,榜首與第十名得分差已從11.9%降至5.4%。
5. AI邏輯短板,推理能力仍是瓶頸
采用符號推理方法的AI系統(tǒng),能較好解決IMO問題(雖未達人類頂尖水平),但LLM在MMMU等復雜推理任務(wù)中表現(xiàn)欠佳,尤其不擅長算術(shù)推導和規(guī)劃類強邏輯性任務(wù)。
這一局限影響了其在醫(yī)療診斷等高風險場景的應用可靠性。
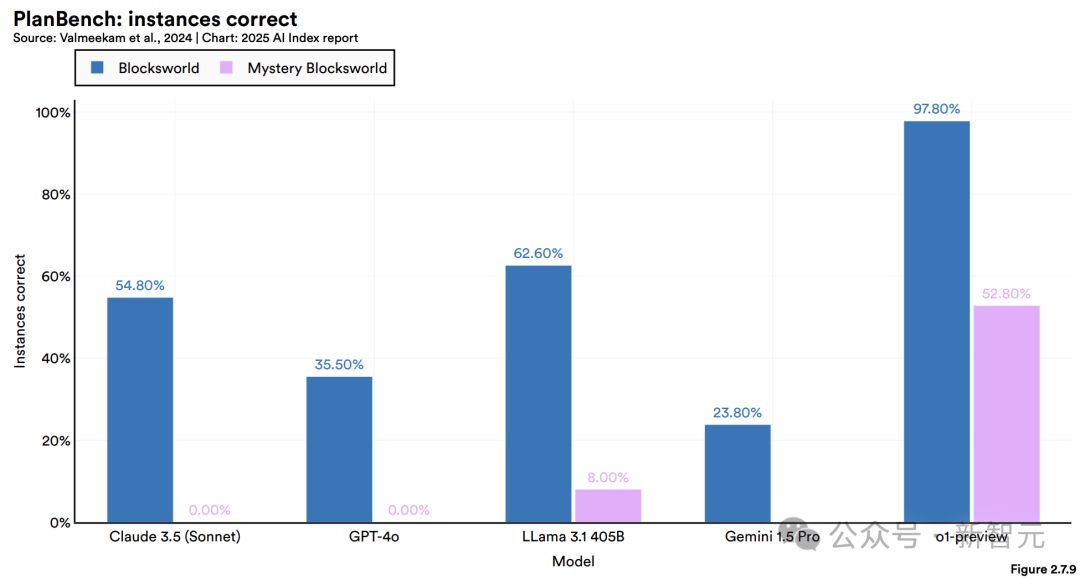
6. 大廠ALL in AI,投資與采用率創(chuàng)雙紀錄
科技大廠們,正全力押注AI。
2024年,美國私營AI投資達1091億美元,約為中國(93億)的12倍、英國(45億)的24倍。
生成式AI勢頭尤猛,全球私募投資達339億美元(同比增18.7%)。
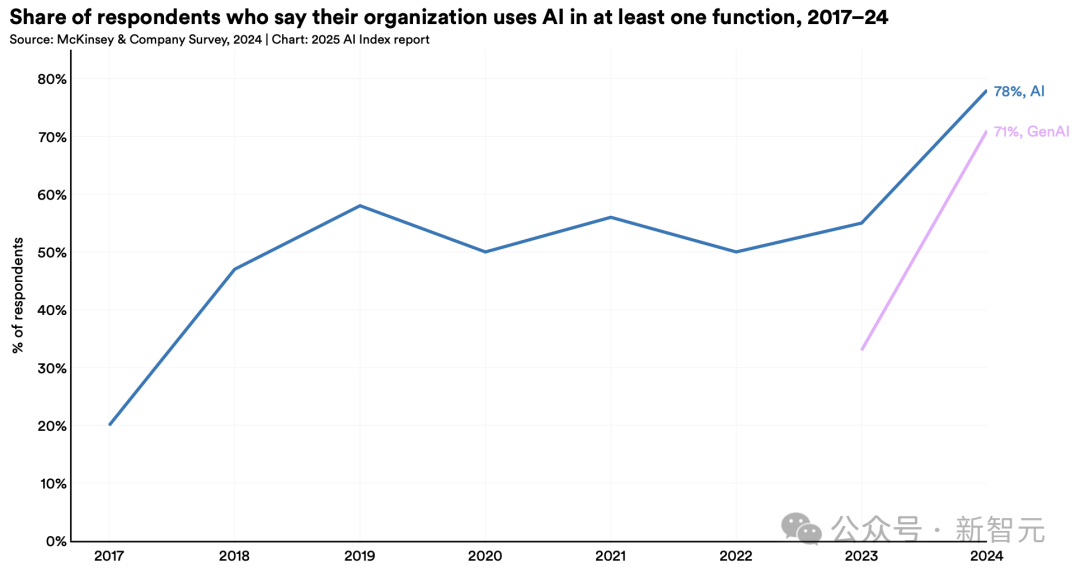
與此同時,企業(yè)AI采用率從55%升至78%。研究證實,AI不僅能提升生產(chǎn)力,多數(shù)情況下還可縮小勞動力技能差距。
更引人注目的是,將生成式AI應用于至少一項業(yè)務(wù)職能的企業(yè)數(shù)量激增——從2023年的33%躍升至去年的71%,增幅超一倍。
7. AI榮膺科學界最高榮譽,摘諾獎桂冠
2024年,兩項諾貝爾獎分別授予深度學習理論基礎(chǔ)(物理學)和蛋白質(zhì)折疊預測(化學)研究,圖靈獎則花落強化學習領(lǐng)域。
8. AI教育普及加速,但資源差距仍存
全球2/3國家已或計劃開展K-12計算機科學教育,但非洲地區(qū)受限于電力等基礎(chǔ)設(shè)施,推進緩慢。
美國81%的計算機教師認為AI應納入基礎(chǔ)課程,但僅47%具備相應教學能力。
9. AI正深度融入日常生活
從醫(yī)療到交通,AI正快速從實驗室走向現(xiàn)實。
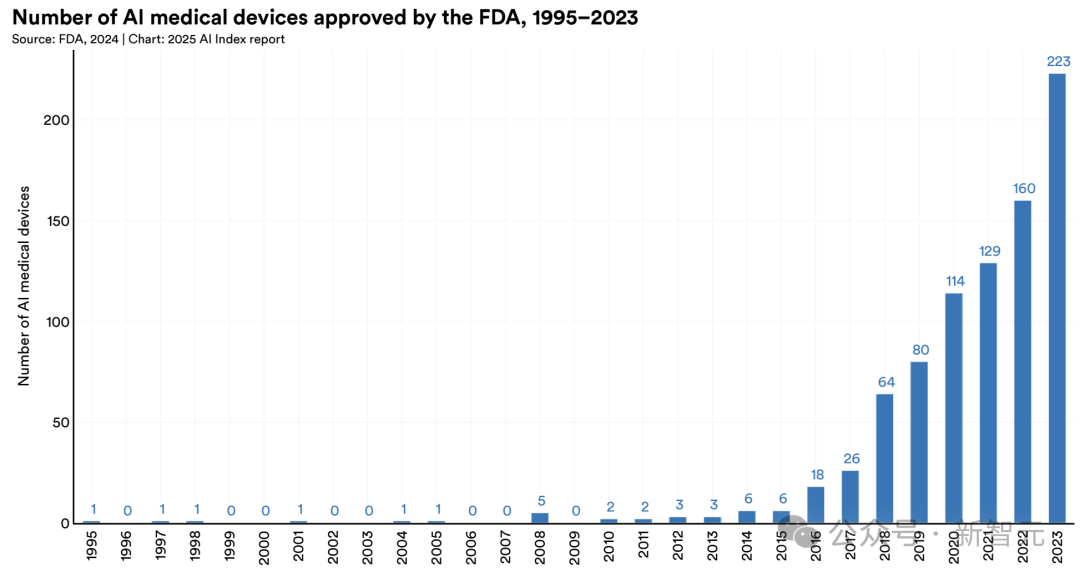
1995年,F(xiàn)DA批準了第一款AI賦能的醫(yī)療器械。
截至2024年8月,F(xiàn)DA已批準950款AI醫(yī)療設(shè)備——較2015年的6款和2023年的221款,增長迅猛。
而在自動駕駛領(lǐng)域,汽車已脫離實驗階段:美國頭部運營商Waymo每周提供超15萬次無人駕駛服務(wù)。
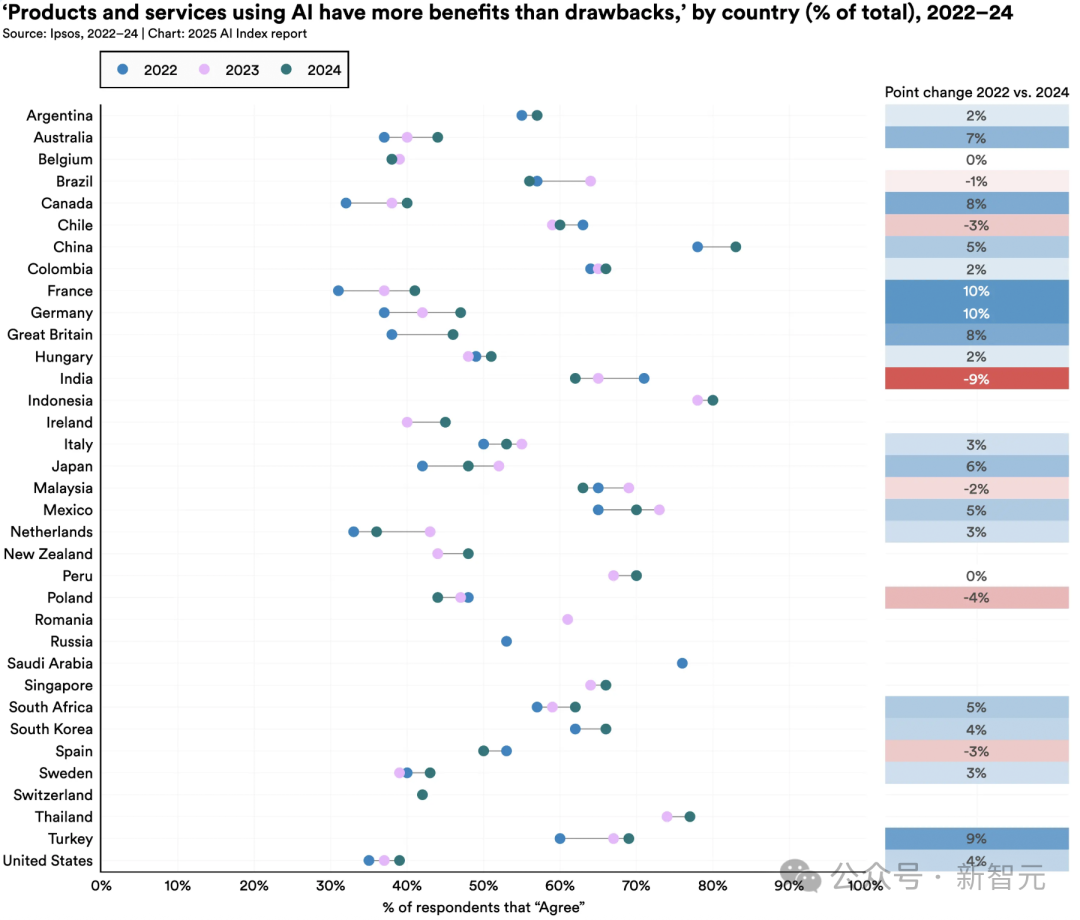
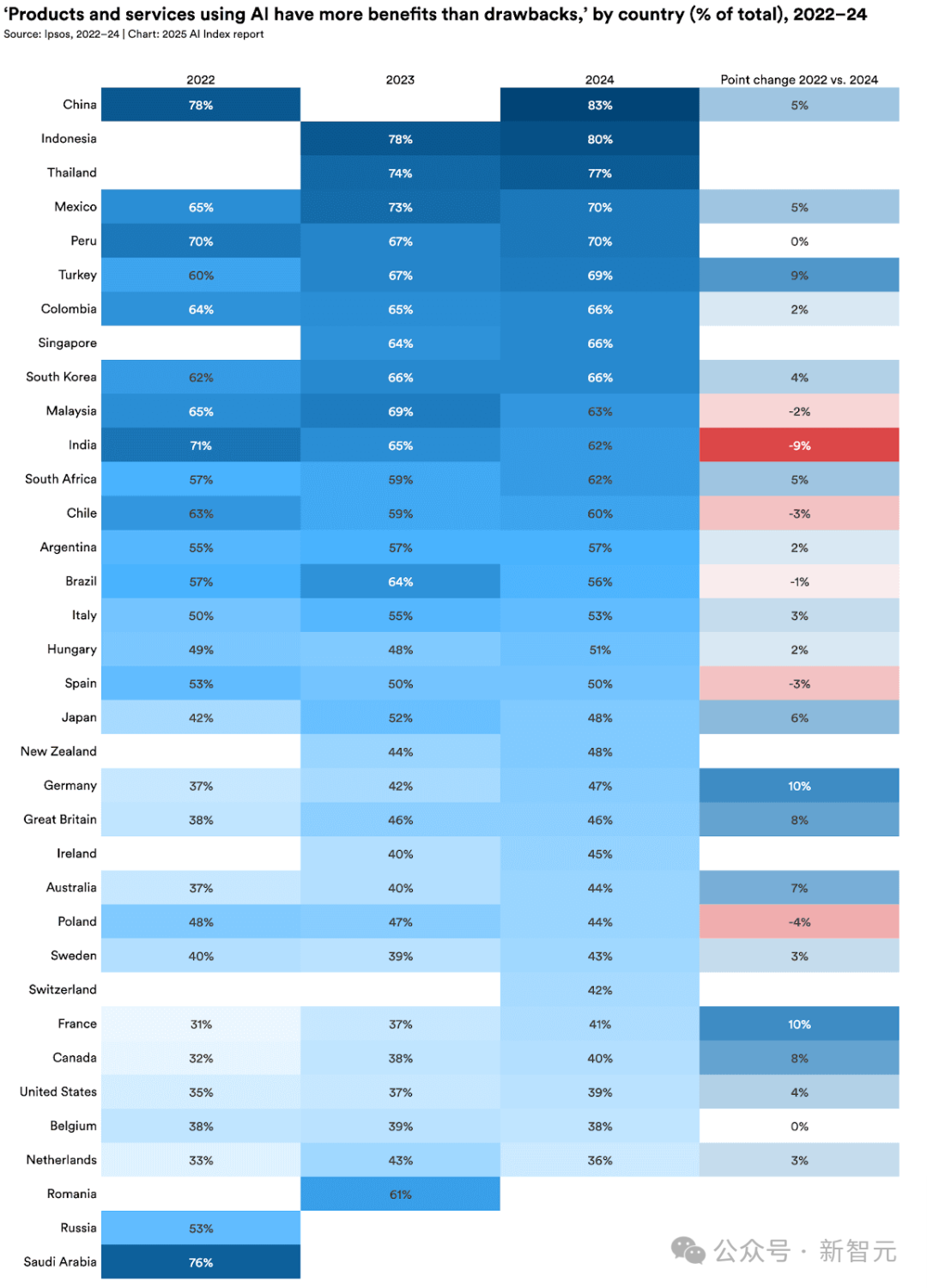
10. 全球AI樂觀情緒上升,但地區(qū)差異顯著
中國(83%)、印尼(80%)和泰國(77%)民眾對AI持積極態(tài)度,而加拿大(40%)、美國(39%)等發(fā)達國家則相對保守。
值得關(guān)注的是,德國(+10%)、法國(+10%)等原懷疑論國家態(tài)度明顯轉(zhuǎn)變。
11. 負責任AI生態(tài)發(fā)展不均
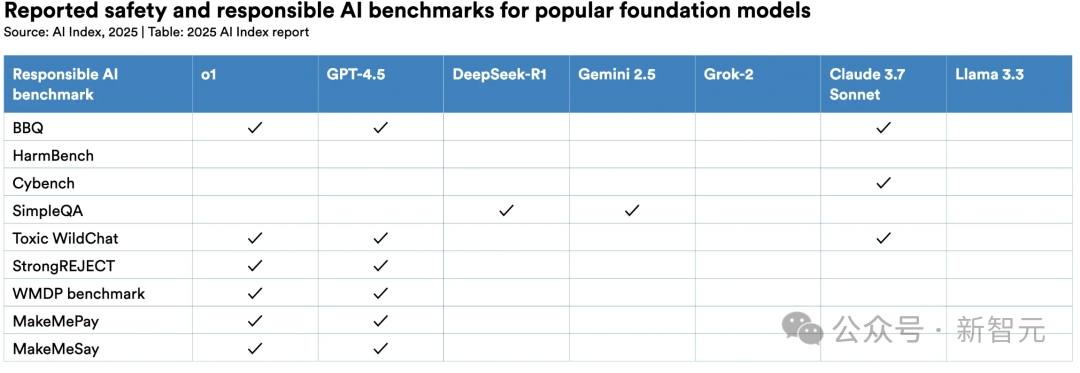
雖然AI安全事件激增,但主流模型開發(fā)商仍缺乏標準化評估體系。
HELM Safety、AIR-Bench和FACTS等新基準為事實性與安全性評估提供工具。
企業(yè)普遍存在「認知與行動脫節(jié)」,而各國政府加速協(xié)作:2024年,經(jīng)合組織、歐盟等國際機構(gòu)相繼發(fā)布聚焦透明度、可信度的治理框架。
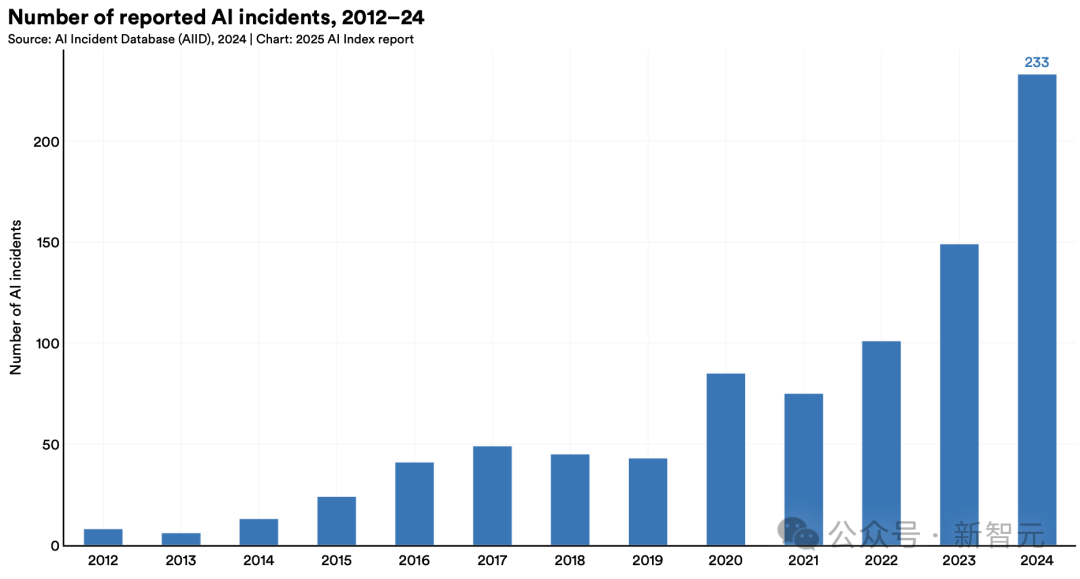
· 問題AI數(shù)量躍升
根據(jù)權(quán)威AI危害追蹤數(shù)據(jù)庫「AI事件庫」(AI Incidents Database)統(tǒng)計,2024年全球AI相關(guān)危害事件激增至233起,創(chuàng)下歷史新高,較2023年暴漲56.4%。
其中既包括深度偽造私密圖像案件,也涉及聊天機器人疑似導致青少年自殺等惡性事件。
盡管該統(tǒng)計未能涵蓋全部案例,但已清晰揭示AI技術(shù)濫用正在呈現(xiàn)驚人增長態(tài)勢。
12. 全球監(jiān)管力度持續(xù)加強
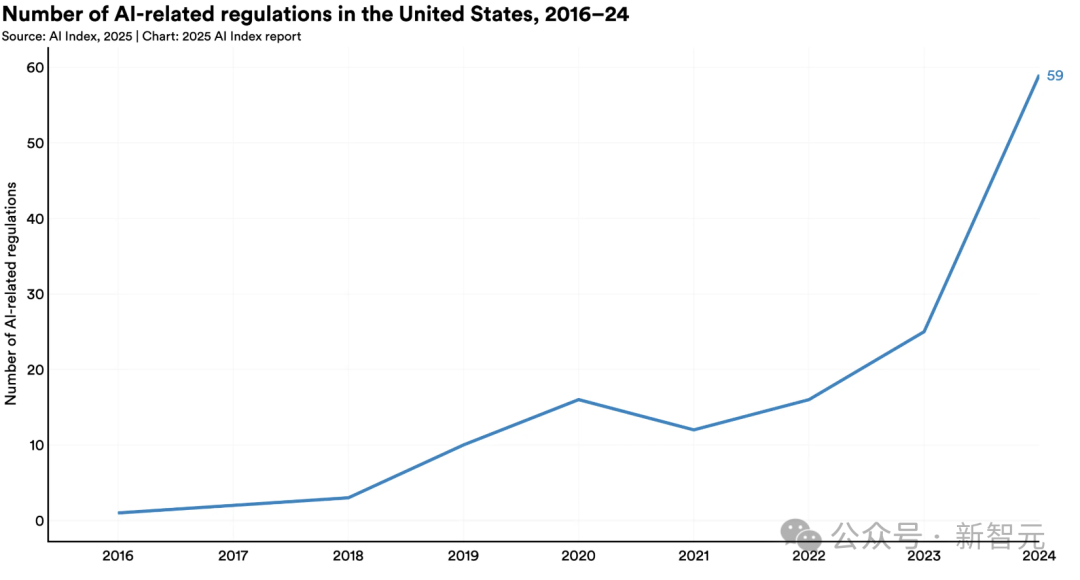
2024年美國聯(lián)邦機構(gòu)頒布59項AI法規(guī),涉及部門數(shù)量翻倍。
75個國家立法機構(gòu)提及AI頻次同比增長21.3%,較2016年增長九倍。
投資方面:加拿大承諾24億美元,中國設(shè)立475億美元半導體基金,法國投入1090億歐元,印度撥款12.5億美元,沙特啟動千億美元級的「超越計劃」。

詳細亮點解讀
下面,我們將摘出報告中的亮點內(nèi)容,提供更詳細的解讀。
中美差距僅剩0.3%
翻開502頁的報告,最吸睛的部分,莫過于中美AI差異這部分了。


報告中強調(diào),雖然2024年,美國在頂尖AI模型的研發(fā)上依然領(lǐng)先,但中美模型之間的性能差距,正在迅速縮小!
為了衡量AI領(lǐng)域過去一年演變的全球格局,HAI特意用AI指數(shù),列出了具有代表性的模型所屬國家,美國依然居首。
數(shù)據(jù)顯示,在2024年,美國機構(gòu)以擁有40個知名模型領(lǐng)先,遠遠超過中國的15個和歐洲的3個。
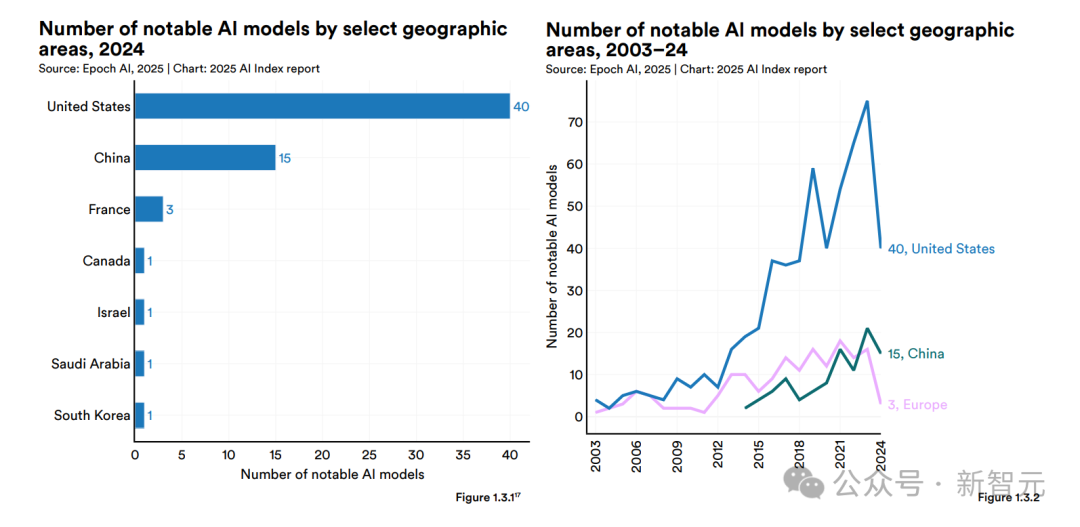
總體來說,模型發(fā)布總量已經(jīng)下降,可能是多個因素共同導致的,比如訓練規(guī)模日益龐大、AI技術(shù)日益復雜,開發(fā)新模型方法的難度也在增加。
AI模型已成為算力巨獸

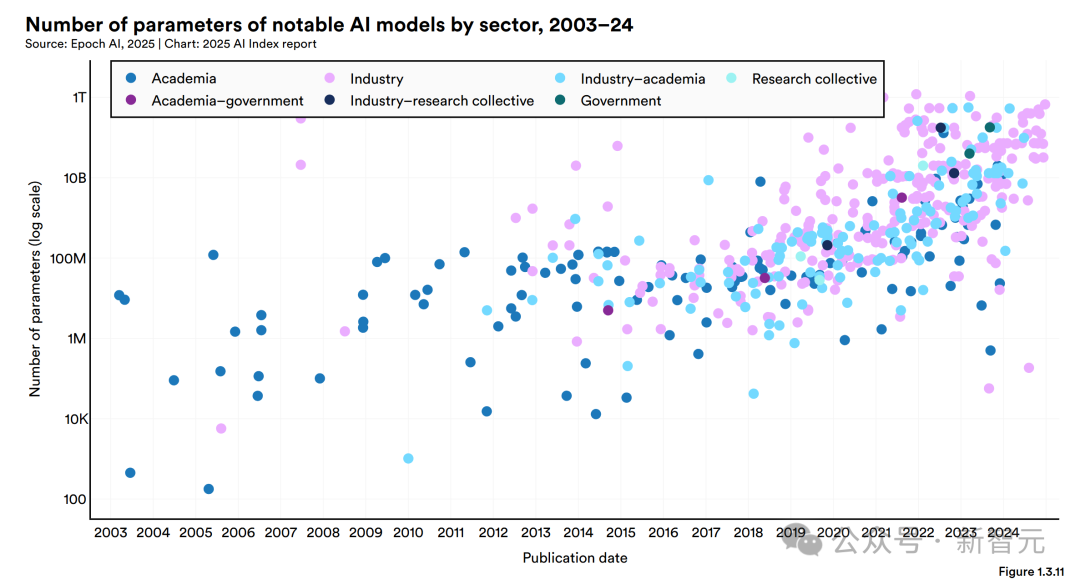
· 參數(shù)趨勢
簡單的說,參數(shù)就是AI模型通過訓練學到的一些數(shù)字,這些數(shù)字決定了模型如何理解輸入和怎樣輸出。
AI的參數(shù)越多需要的訓練數(shù)據(jù)也越多,但同時性能也更厲害。
從2010年代初開始,模型的參數(shù)量就蹭蹭往上漲,這背后是因為模型設(shè)計得越來越復雜、數(shù)據(jù)更容易獲取、硬件算力也更強了。
更重要的是,大模型確實效果好。
下圖用了對數(shù)刻度,方便大家看清楚AI模型參數(shù)和算力近年來的爆炸式增長。
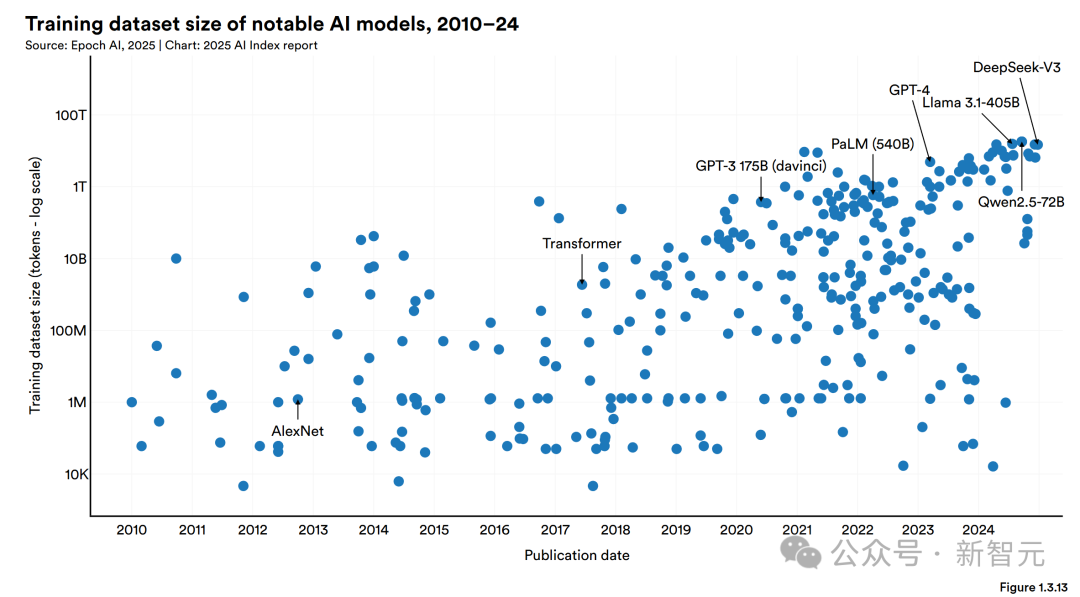
隨著模型參數(shù)數(shù)量的增加,訓練所需的數(shù)據(jù)量也在暴漲。
2017年發(fā)布的Transformer模型,掀起了大型語言模型的熱潮,當時它用了大約20億個token來訓練。
到了2020年,GPT-3 175B模型的訓練數(shù)據(jù)已經(jīng)飆到了約3740億個token。
而Meta在2024年夏天發(fā)布的模型Llama 3.3,更是用了大約15萬億個token來訓練。
根據(jù)Epoch AI的數(shù)據(jù),大型語言模型的訓練數(shù)據(jù)集規(guī)模大約每八個月翻一倍。
訓練數(shù)據(jù)集越來越大,導致的訓練時間也變得越來越長。
像Llama 3.1-405B這樣的模型,訓練大概需要90天,這在如今已經(jīng)算是「正常」的了。
谷歌在2023年底發(fā)布的Gemini 1.0 Ultra,訓練時間大約是100天。
相比之下,2012年的AlexNet就顯得快多了,訓練只花了五六天,而且AlexNet當時用的硬件還遠沒有現(xiàn)在的先進。
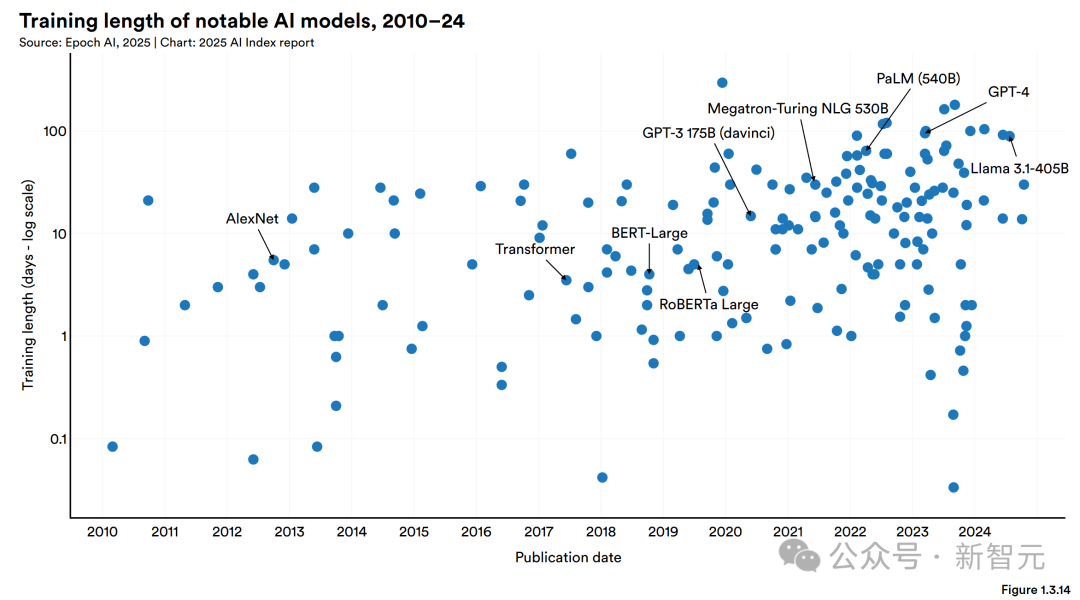
· 算力趨勢
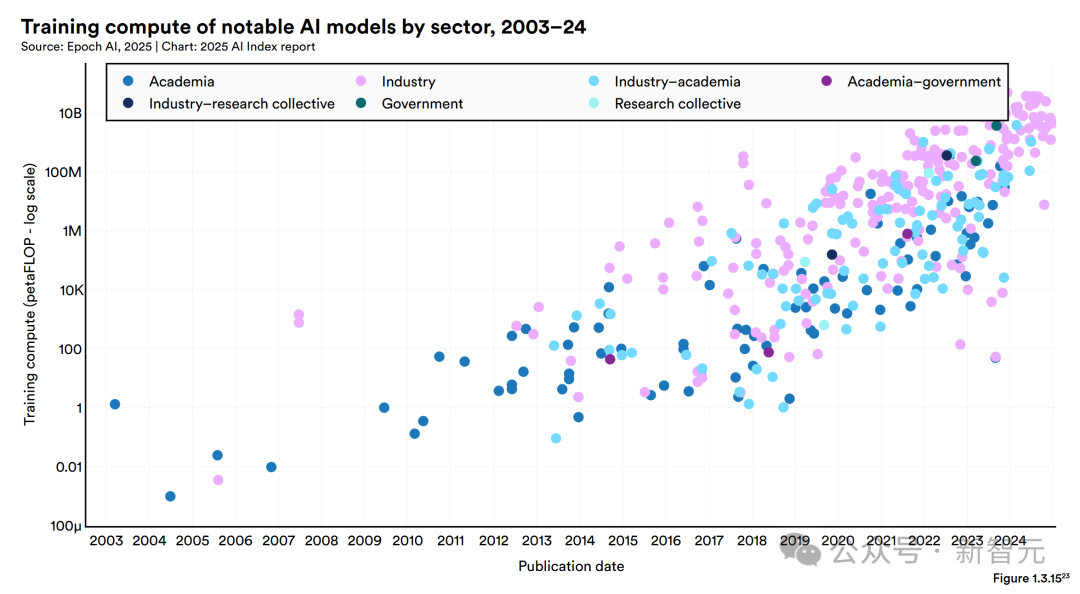
「算力」指的是訓練和運行AI模型所需的計算資源。
最近,知名AI模型的算力消耗呈指數(shù)級增長。據(jù)Epoch AI估計,知名AI模型的訓練算力大約每五個月翻一番。
這種趨勢在過去五年尤為明顯。
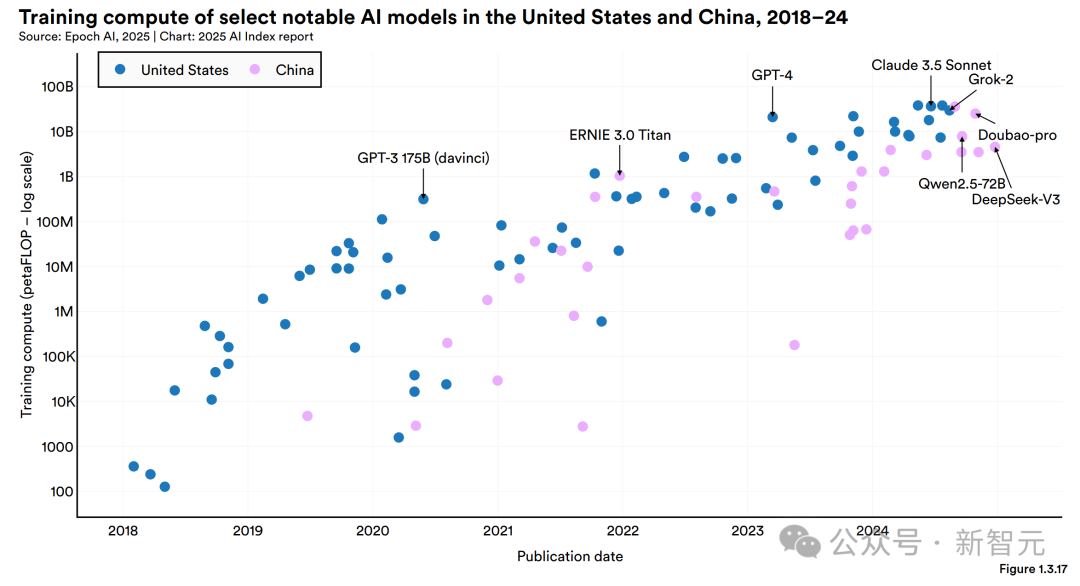
去年12月,DeepSeek V3一經(jīng)推出就引發(fā)了廣泛關(guān)注,主要就是因為它在性能上極其出色,但用的計算資源卻比許多頂尖大型語言模型少得多。
下圖1.3.17比較了中國和美國知名AI模型的訓練算力,揭示了一個重要趨勢:美國的頂級AI模型通常比中國模型需要多得多的計算資源。
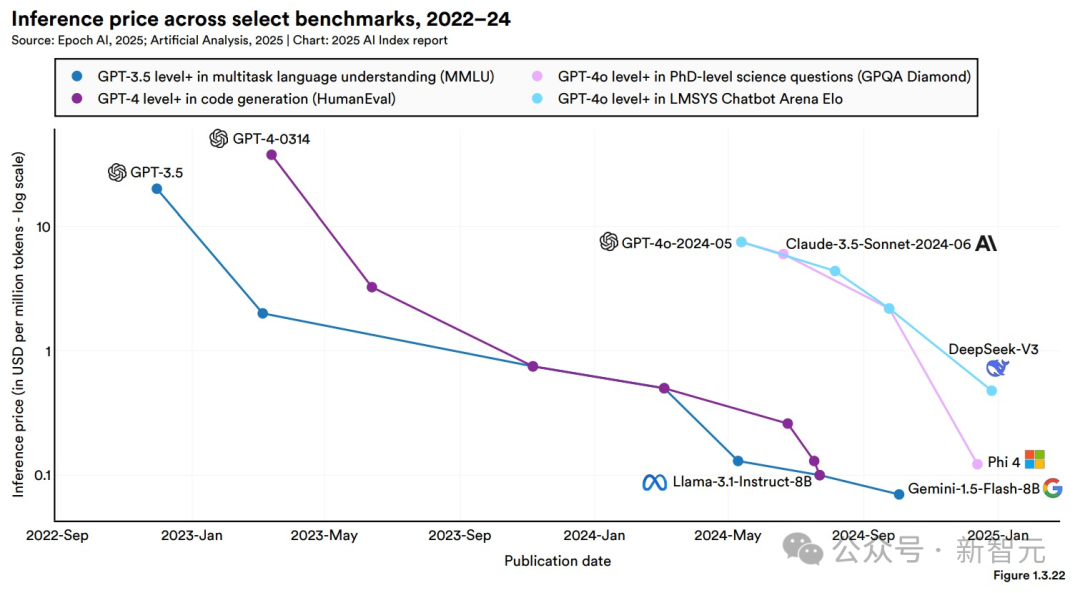
· 推理成本
推理成本,指的是對一個已訓練模型進行查詢所需的費用,通常以「每百萬tokens的美元價格」來衡量。
這份報告中AI token的價格數(shù)據(jù),來源于Artificial Analysis和Epoch AI的API定價專有數(shù)據(jù)庫,而價格是根據(jù)輸入與輸出token的價格按3:1的權(quán)重平均計算得出的。
可以看出,單位性能的AI成本正在顯著下降。
而Epoch AI估計,根據(jù)不同任務(wù)類型,大型語言模型的推理成本每年下降幅度可達9倍至900倍不等。
雖然如此,想要獲得來自O(shè)penAI、Meta和Anthropic的模型,仍需支付不小的溢價。
· 訓練成本
雖然很少有AI公司披露具體的訓練成本,但這個數(shù)字普遍已達到數(shù)百位美元。
OpenAI CEO奧特曼曾表示,訓練GPT-4的訓練成本超過了1億美元。
Anthropic的CEO Dario Amodei指出,目前正在訓練的模型,成本約為10億美元。
DeepSeek-V3的600萬美元,則打破了新低。

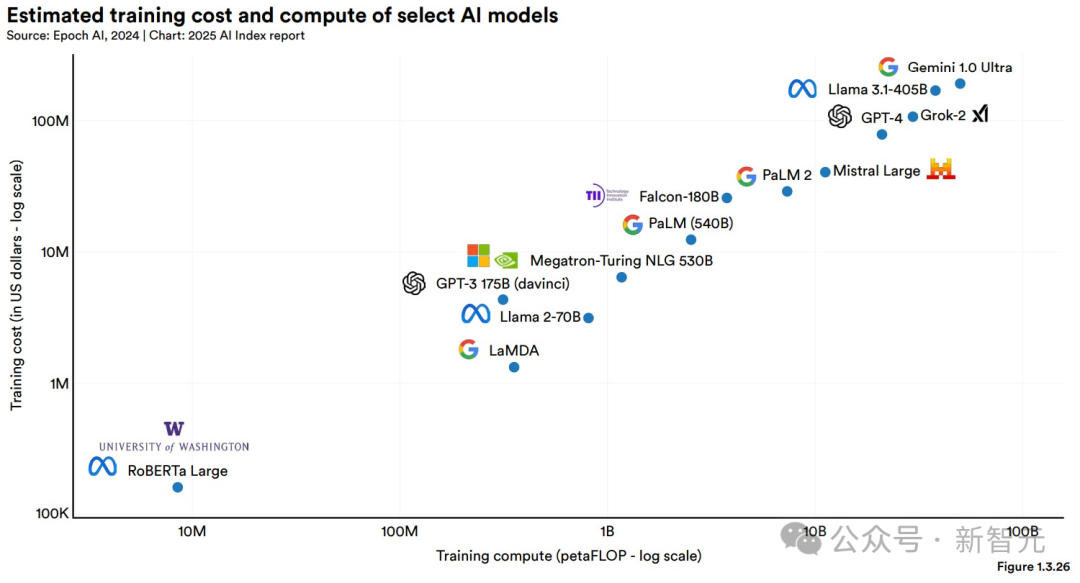
圖1.3.24展示了基于云計算租賃價格的部分AI模型的訓練成本估算。
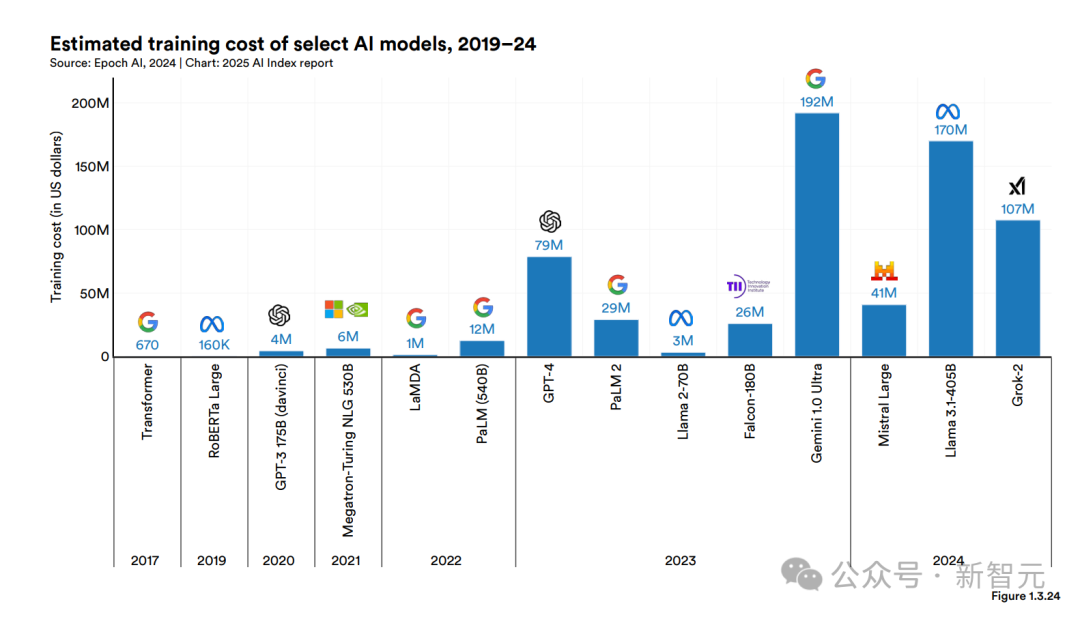
圖1.3.25展示了AI指數(shù)所估算的所有AI模型的訓練成本。
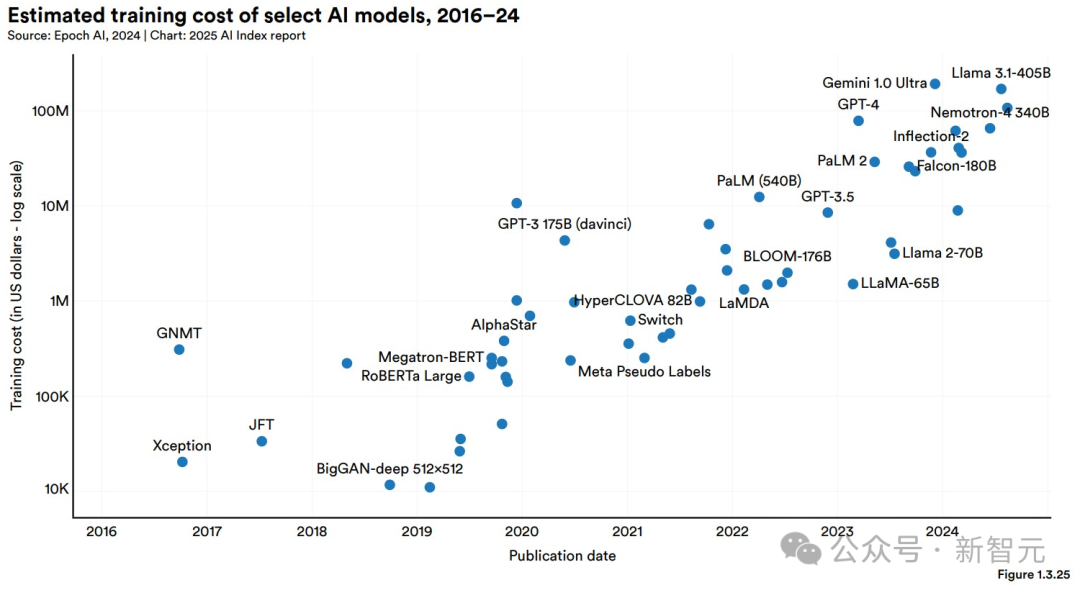
在2024年,Epoch能估算的少數(shù)模型之一,就是Llama 3.1-405B,訓練成本約為1.7億美元。
另外,AI模型的訓練成本與其計算需求之間存在直接的關(guān)聯(lián)。如圖1.3.26所示,計算需求更大的模型訓練成本顯著更高。